
US Government Spending On Kids
TidyTuesday
Join the R4DS Online Learning Community in the weekly #TidyTuesday event! Every week we post a raw dataset, a chart or article related to that dataset, and ask you to explore the data. While the dataset will be “tamed”, it will not always be tidy! As such you might need to apply various R for Data Science techniques to wrangle the data into a true tidy format. The goal of TidyTuesday is to apply your R skills, get feedback, explore other’s work, and connect with the greater #RStats community! As such we encourage everyone of all skills to participate!
Acknowledgements
The data from which the following analysis and visualizations are based on is provided from Urban Institute courtesy of Joshua Rosenburg’s tidykids R package.
Load the weekly Data
kids <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-09-15/kids.csv')Exploring the data
colnames(kids)## [1] "state" "variable" "year" "raw"
## [5] "inf_adj" "inf_adj_perchild"summary(kids)## state variable year raw
## Length:23460 Length:23460 Min. :1997 Min. : -60139
## Class :character Class :character 1st Qu.:2002 1st Qu.: 71985
## Mode :character Mode :character Median :2006 Median : 252002
## Mean :2006 Mean : 1181359
## 3rd Qu.:2011 3rd Qu.: 836324
## Max. :2016 Max. :83666088
## NA's :102
## inf_adj inf_adj_perchild
## Min. : -60799 Min. :-0.01361
## 1st Qu.: 85876 1st Qu.: 0.12456
## Median : 298778 Median : 0.32757
## Mean : 1359983 Mean : 0.91448
## 3rd Qu.: 985049 3rd Qu.: 0.83362
## Max. :84584960 Max. :20.27326
## NA's :102 NA's :102length(unique(kids$state))## [1] 51length(unique(kids$variable))## [1] 23Thankfully there are some self-explanatory variables given the subject of the data and light exploration of the package codebook.
State is the 50 US States plus Washington DC.
Year is self-explanatory.
Consulting the
tidykidspackage codebook provides that variable is a categorical variable depicting the category for public spending.raw, inf_adj, and inf_adj_perchild are numeric variables measuring the raw amount of dollars spent per state/year/variable level, then that raw amount is adjusted for inflation to the then current 2016 rate, and lastly that adjusted amount is divided by that state’s population of children. All of these financial variables are measured in thousands.
How This is Read
kids %>% arrange(desc(inf_adj_perchild)) %>% head(1)## # A tibble: 1 x 6
## state variable year raw inf_adj inf_adj_perchild
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 District of Columbia other_health 2016 2629563 2629563 20.3kids %>% arrange(desc(inf_adj)) %>% head(1)## # A tibble: 1 x 6
## state variable year raw inf_adj inf_adj_perchild
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 California other_health 2015 83666088 84584960 8.76So, to give an example of how we can read this table output from code above: in 2016, Washington DC spent a total of $2,629,563,000 or roughly $20k per child in the ‘other_health’ variable, which is defined from the codebook as “public spending on health vendor payments and public hospitals, excluding Medicaid…”
That sounds like a lot of money, but it sounds in line with other observations when we consider that - adjusting for inflation - California spent $84,584,960,000 also in other_health just a year prior.
I wonder if other_health is consistently the most expensive form of public spending on children by states. Before we begin to start researching these questions, we should first understand if there are any errors in our data or the possibility to make errors in our analysis by not appropriately understanding all aspects of our data.
Tidying the Data
First, it sticks out to me that we have 102 NA values for our 3 financial variables. This could mean we are missing values for two separate variables for all 51 unique ‘states.’ Let’s see.
unique(kids %>% filter(is.na(kids$raw) == TRUE) %>% select(variable))## # A tibble: 2 x 1
## variable
## <chr>
## 1 Medicaid_CHIP
## 2 other_healthunique(kids %>% filter(is.na(kids$raw) == TRUE) %>% select(year))## # A tibble: 1 x 1
## year
## <dbl>
## 1 1997summary(kids %>% filter(!is.na(kids$raw)))## state variable year raw
## Length:23358 Length:23358 Min. :1997 Min. : -60139
## Class :character Class :character 1st Qu.:2002 1st Qu.: 71985
## Mode :character Mode :character Median :2007 Median : 252002
## Mean :2007 Mean : 1181359
## 3rd Qu.:2012 3rd Qu.: 836324
## Max. :2016 Max. :83666088
## inf_adj inf_adj_perchild
## Min. : -60799 Min. :-0.01361
## 1st Qu.: 85876 1st Qu.: 0.12456
## Median : 298778 Median : 0.32757
## Mean : 1359983 Mean : 0.91448
## 3rd Qu.: 985049 3rd Qu.: 0.83362
## Max. :84584960 Max. :20.27326Just as suspected we have 102 NA variables because in the year 1997 all 51 ‘states’ did not spend on Medicaid_CHIP or other_health. It’s an important thing to consider whether this means the data for spending in those variables were not available, if those variables did not exist yet, if NA in this case means 0. For now, we’ll keep our NA values.
Now that we’ve clarified the existence of our NA values, another thing to be noticed is that there are negative values for raw, and therefore subsequently negative values for inf_adj and inf_adj_perchild. How many negative values do we have?
kids %>% filter(raw < 0)## # A tibble: 4 x 6
## state variable year raw inf_adj inf_adj_perchild
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Arizona TANFbasic 2013 -21820. -22729. -0.0133
## 2 New York edservs 2014 -34674 -35468. -0.00790
## 3 New York edservs 2015 -60139 -60799. -0.0136
## 4 New York edservs 2016 -18342 -18342 -0.00413Four different negative values for two states and for two types of spending. A quick consultation to the codebook clears up that the one negative value for Arizona in TANFbasic spending is due to an accounting adjustment for overreporting spending in expenditures in previous years. OK, that makes sense. Arizona reported themselves as having spent more than they actually did in previous years, so to balance the ledger they took that away from their spending in 2013, showing how they ended up spending a negative amount.
What about New York for edservs spending. The codebook here also says that edservs spending is derived from “Public spending on education special services by state and year… expenditure less private revenue from Other Education Charges.” OK so I suppose in these 3 years, New York made more money from education special services than they had to spend for the same services. That seems plausible, but it’s hard to say for sure given that thetidykids package is data itself transcribed from the Census Bureau’s annual State and Local Government Finance Survey. It’s essentially a game of data telephone.
The data is now tidy, to the best of our ability. We may not know how to resolve the confusion given our negative values, but knowing there is in itself some ambiguity makes us that much more responsible in our treatment of the data.
Answering Questions
## [1] "PK12ed" "highered" "edsubs" "edservs"
## [5] "pell" "HeadStartPriv" "TANFbasic" "othercashserv"
## [9] "SNAP" "socsec" "fedSSI" "fedEITC"
## [13] "CTC" "addCC" "stateEITC" "unemp"
## [17] "wcomp" "Medicaid_CHIP" "pubhealth" "other_health"
## [21] "HCD" "lib" "parkrec"Now that our data is ‘tidy’ we can begin to answer questions that we’re interested in. I have to say, a lot of these variables around government spending don’t interest me too much. I believe the first 6 variables below are related to education - whether it be primary & secondary, higher education, grants, subsidies, or related educational programs. I might combine these 6 and aggregate them to one ‘education’ spending variable. The balance of variables are related to social programs, tax programs, libraries, and parks and recreation services. For this analysis I want to firstly see if on average other_health is the highest government spending variable when adjusted for inflation, or if this top position wavers between different variables.
Otherwise, I’m interested in knowing just how much these states are investing in public education, libraries, and parks & rec services. People have a tendency to relate to something more if it’s about them, so I’m going to do just that with this data. For these three spending variables, I’m going to observe spending patterns chronologically only for states that I have lived in (one month or more) or states that I plan to live in. So, that’ll be New Jersey, New York, Pennsylvania, Texas, and Washington.
Besides this imposed constraint on the data, there’s actually also an inherent way this data intersects with my life. The government spending is tracked from 1997 to 2016. Without saying too much about my age, these are crucial years that will really make me wonder whether I would’ve had a better education and childhood in one of these states above the others given their public spending in my chosen categories of interest.
The Highest Government Spending Variable In the Nation

Of course, there are far too many variables to be able to reliably discern what colors are the top two variables. My hope is that PK12ed is #1 (I just hope the nation cares about child education that much) and my guess is that other_health is #2. There are 40 unique year/variable combos we’re measuring (but recall we deleted one year for an NA value in other_health), so if I arrange descending by inf_adj then it should be relatively in order of the two top variables for the top 39 entries.
unique(kids_nation_aggregate %>% arrange(desc(inf_adj)) %$% variable[1:39])## [1] "PK12ed" "other_health"So, at the national level, the highest spending was PK12ed and the second highest was other_health. Glad my hopes were proven true. Do any individual states deviate from this aggregate observation?
The Highest Government Spending Variable by State
If other_health and PK12ed are the top two spending variables for each state in each year, then a list of variable names arranged by state, year, and descending on inf_adj should have either of those two variables as the first two for every 23 entries. Otherwise, any other variable names would mean for that given state and year that other variable would have been either #1 or #2. Let’s code this.
#This makes the data frame for the top two spending variables per state/year
kids_top_two_per_state <- kids %>% select(state, year, variable, inf_adj) %>% arrange(state, year, desc(inf_adj)) %>% slice(unlist(lapply(23*(0:1019), `+` , 1:2)))
#this checks what those unique variables are
unique(kids_top_two_per_state$variable)## [1] "PK12ed" "highered" "other_health" "Medicaid_CHIP"
## [5] "pubhealth" "othercashserv" "fedEITC" "unemp"
## [9] "wcomp"#this filters to and names the states that spent in something else than our variables of interest as a top 2 variable for a given year
unique(kids_top_two_per_state %>% filter(!variable %in% c('other_health' , 'PK12ed'), year != 1997) %$% state)## [1] "Arizona" "Nevada" "North Dakota" "Vermont"#This fitlers our saved DF for the named states and then plots the top two spending variables for each year in those states
kids_top_two_per_state %>% filter(state %in% c('Arizona' , 'North Dakota' , 'Nevada' , 'Vermont') ,
#Starting now we'll begin filtering out 1997, since other_health was NA for that year
year != 1997) %>% ggplot(aes(year, inf_adj)) + geom_point(aes(color = variable)) + facet_grid(~state , scales = 'free') + labs(title= 'Top 2 spending variables', subtitle = 'Of states that had top two other than other_health or PK12ed in any year') + theme(axis.text.x = element_text(angle = -90 , vjust = 0.2) )
I know very little about these states, but I would have never believed Arizona spends so much more in education compared to Vermont!
So there we have it - only 4 states have deviated from the national pattern that other_health and PK12ed are the top two spending variables. Nevada really stands out to me as only having one year in which they deviated from the pattern and their spending in unemployment supplanted other_health in 2010. I wonder if this was in response to a large unemployment crisis in the country at large and particularly felt by Nevada. These are questions for another time, I’ll opt to stay on track with how this affects me.
Who has the ‘best’ education?
It’s time to begin seeing how this data intersects with my life. Of the states I’ve lived in, how do they compare in educational spending? I don’t want to observe only the PK12ed variable. I want to know how they line up in the summed aggregate of their educational spending variables. Time to pivot.
kids_my_variables <- kids %>% pivot_wider(id_cols = c('state', 'year'), names_from = 'variable', values_from = 'inf_adj_perchild') %>% mutate(education_agg = PK12ed + highered + edsubs + edservs + pell + HeadStartPriv) %>% select(state, year, education_agg, lib, parkrec)
reactable(kids_my_variables %>% arrange(desc(education_agg)) %>% select(State = state,Year = year, `Amount Spent Per Kid in Education (USD thousands)` = education_agg), filterable = TRUE, resizable = TRUE)To reconsider this relationship between budget and education, let’s observe the ratio of educational spending to total spending and consider its implications.
kids_my_variables <- kids %>% pivot_wider(id_cols = c('state','year') , names_from = 'variable' , values_from = 'inf_adj') %>% mutate(fips = fips(state), total = rowSums(.[3:25], na.rm = TRUE), education_agg = PK12ed + highered + edsubs + edservs + pell + HeadStartPriv, education_pcnt = (round(education_agg / total, 2)*100) , lib_pcnt = ((lib / total)*100) , park_pcnt = (round(parkrec / total,2))*100) %>% select(fips, state, year, education = education_pcnt, libraries = lib_pcnt, `parks & rec` = park_pcnt, total)
for (x in c('education','libraries','parks & rec')){
print(plot_usmap(data = kids_my_variables %>% filter(year == #arbitrarily chosen year
2002), values = x , labels = FALSE) + scale_fill_continuous(low = 'white' , high = 'red' , name = paste('% of spending on',x, '(2002)')) + theme(legend.position = 'right') +labs(title = paste('Map of', x,'spending as a % of total state government spending on children')))
}


I decided to skip forward a few steps and plot the ratio for libraries and parks & services. We’ll come back to this later, but I’d like to say briefly: the proportion of the budget that gets spent on libraries is dismal :(
As for education, this new plot shows potentially how seriously each state treats education. While Washington DC might spend $20k per child in a given year for their education, compared to Utah that might spend $5k, perhaps to DC that is only 30% of their overall spending, whereas that $5k for Utah is a higher portion of their overall spending.
Let’s take out all the states that don’t pertain to me and take a look again.
edu_plot <- plot_usmap(include = c('New Jersey','New York','Pennsylvania','Texas','Washington') , data = kids_my_variables %>% filter(year == 2002), values = 'education') + scale_fill_continuous(low = 'white', high = 'red', name = '% of spending on education') + theme(legend.position = 'right') + labs(title = 'Education spending as a % of total gov. spending on children' , subtitle = "In places I've lived for more than a month")
edu_plot
This plot has way too much negative space.
img <- "C:/Users/Nick/Documents/personal-website/static/img/pexels-cdc-3992949.jpg"
ggbackground(edu_plot + theme(legend.text = element_text(color = 'skyblue') , legend.title = element_text(color = 'skyblue'), title = element_text(color = 'skyblue')), img)
Well, I guess the goal was take up negative space, not make it pretty… I Think I’ll explore other viz methods for these questions.
This map plot is only for the year of 2002. I hope that Washington state had a really developed educational system prior to 2002, because that % of spending in education is not encouraging.
New Jersey on the other hand looks like potentially the ideal place to live as a kid if education is the metric. Let’s take a step back and clear up what this actually means and doesn’t necessarily mean.
This is a map plotting the spending in children’s education (that includes primary, secondary education, higher education, special services, grants, and subsidies) as a % of the total amount spent on children for a particular state in a particular year (2002 in this case). It can be easy to think of it as such, but this does not mean that education in a state that pays a higher percentage of their overall budget towards education is better than one that pays a lower percent. New Jersey may have had a lot of problems in their education they needed to address, thus requiring the higher % as indicated by the map.
Now that my caveat is over, let me gloat: I grew up in New Jersey, my education was dope.
Education over time
#removing 1997 to avoid errors in plotting NA values
kids_my_variables <- kids_my_variables %>% filter(year != 1997)
p <- plot_usmap(data = kids_my_variables , values = 'education') + scale_fill_continuous(low = 'white' , high = 'red' , name = '% of Total' ) + theme(legend.position = 'right') +
transition_states(year) + ggtitle('Education Spending as a % of Total Child Spending\nby State', subtitle = 'Year : {closest_state}') + labs(caption = 'Source: tidykids package') + theme(plot.title = element_text(size = 40) , plot.subtitle = element_text(size = 30) , plot.caption = element_text(size = 20), legend.title = element_text(size = 25), legend.text = element_text(size = 18))
#commenting out to not save unnecessarily after first iteration
#anim_save('us_edu_spending.gif', animate(p, height = 800, width = 1000))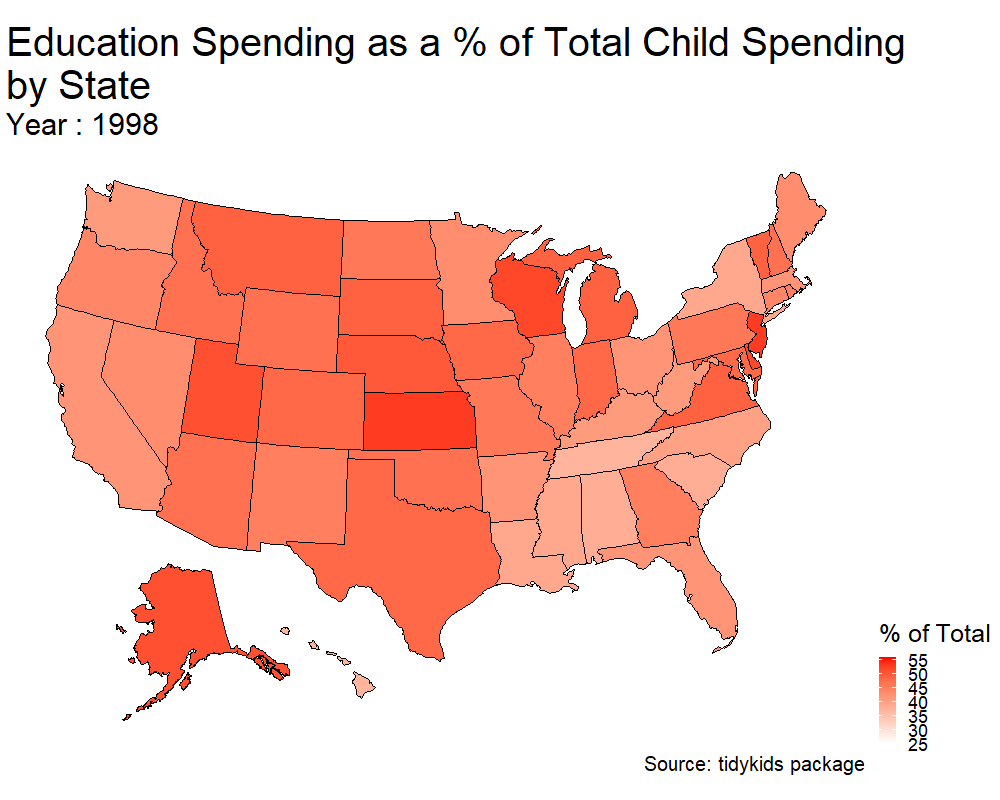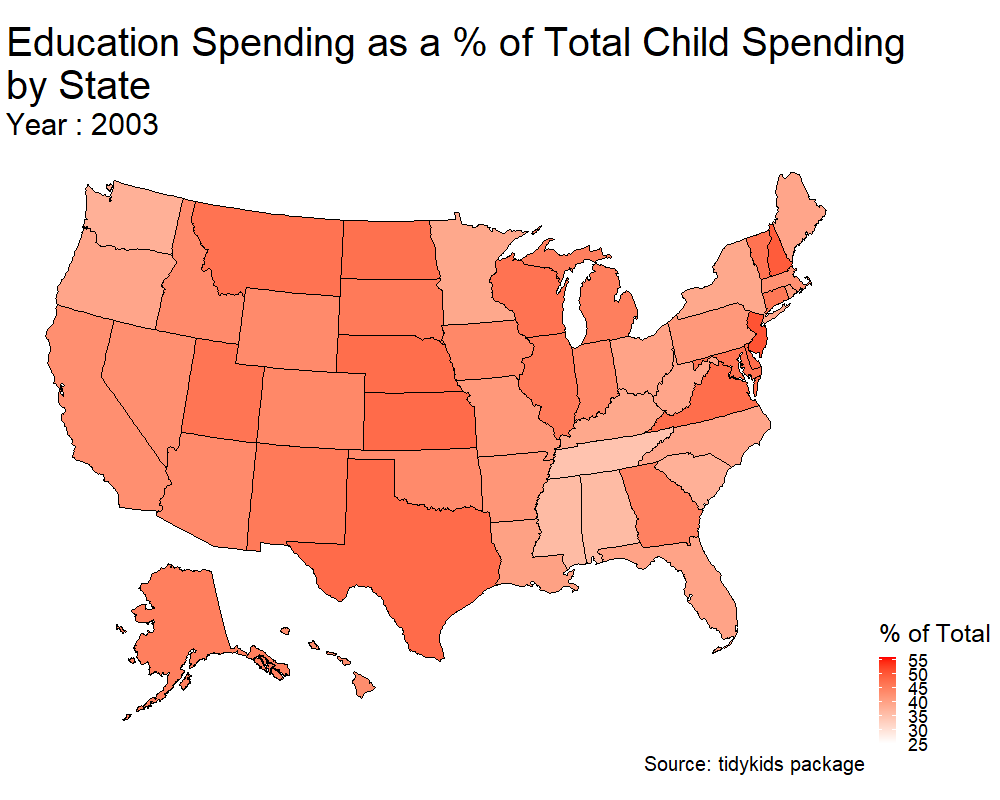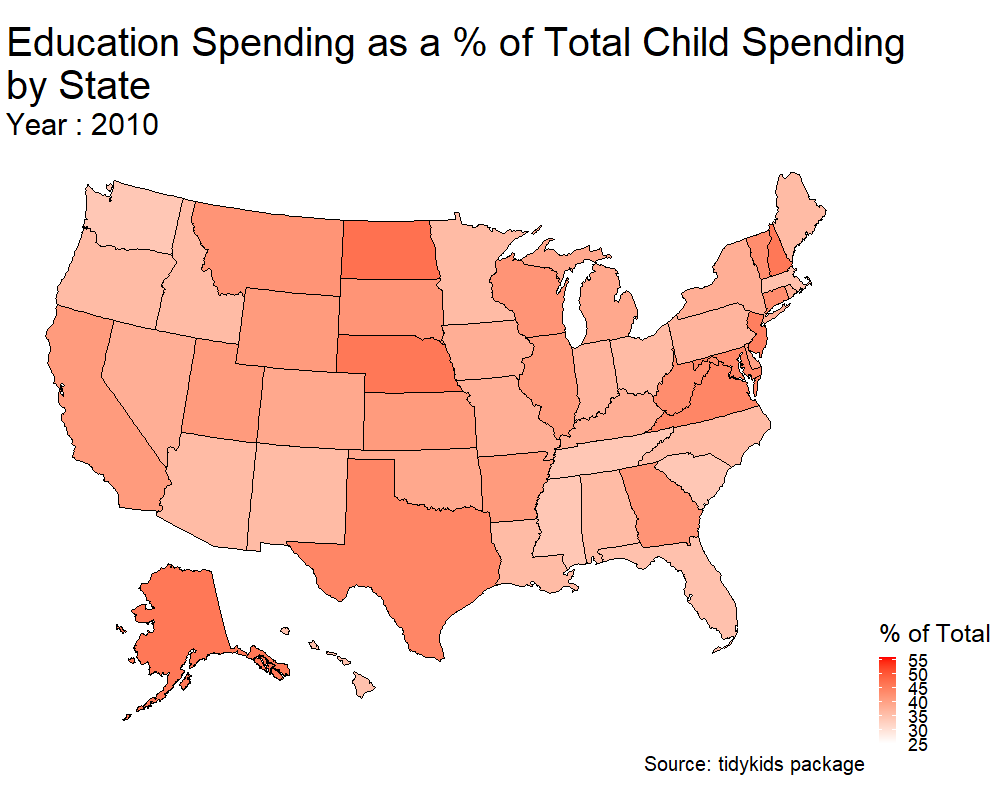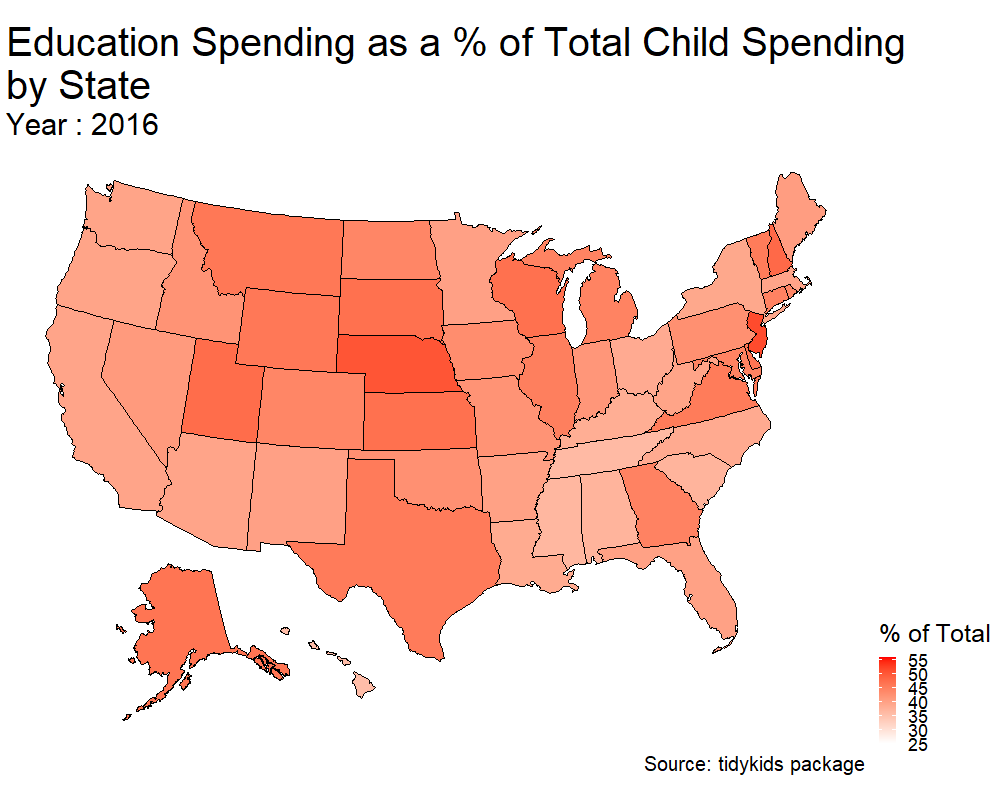
Hooray! This is my first animation using gganimate. Two things I’d like to do from here.
- Cut the percentile to bins for better readability.
- Make this into a
plotlyanimation so a reader can interact with the animation and play/pause as needed.
#This adds state abbreviation to work with plot_geo function from plotly
kids_my_variables <- kids_my_variables %>% mutate(state_abb = state.abb[match(kids_my_variables$state, state.name)], libraries = round(libraries, 2), hover = paste(state, '\n', "Education %", education, '\n', "Libraries %", libraries, "\n",
"Parks & Rec %", `parks & rec`))%>%
#Removing Washing DC, as NA for state.abb will throw an error when plotting
filter(is.na(state_abb) == FALSE)
#this creates the SharedData environment necessary for plotly
kids_mv_shared <- SharedData$new(kids_my_variables)
#creating the plotly geo definition as a list
g <- list(
scope = 'usa',
projection = list(type = 'albers usa'),
showlakes = FALSE)
#plotly choropleth map, filterable by year with additional hover info for parks and libraries
fig <- kids_mv_shared %>% plot_geo(locationmode = 'USA-states') %>%
add_trace(z = ~education, text = ~hover, locations = ~state_abb, color = ~education, colors = 'Purples', frame = ~year) %>% colorbar(title = '% of total child spending', limits = c(25, 56)) %>% layout(title = 'Education and loosely related child spending', geo = g)
figThis is also my first plotly choropleth map! I had originally said I wanted to plot educational spending as a binned categorical value, but I decided against this for two reasons.
- Since this is an animation, it doesn’t improve readability too much to bin the variable. Viewers would have to pause the video either way to know the exact difference in a states educational spending for two or more years as they would likely have to pause to get the binned difference.
- The bins would be chosen arbitrarily. We could have used bin widths of 5%, 2%, etc. It’s not meaningful to split up our data nor is it helpful to show that a state spent between x amount and y amount than visualizing they spent a specific x amount.
Our one stop plot
So what is our best recourse to show our variables of interest, for any given state(s) in any given year(s). Well, sometimes the simplest solution is the best.
I know, I know. It’s one helluva line plot - it’s completely unreadable when plotting all 50 states. However, the plotly object has some nice features in regards to interactivity and works better as a line plot for the following reasons:
- We can filter to show/hide individual state lines by clicking their name in the legend.
- We can select one individual state to plot by double clicking that state. We can then add to that filter selection by clicking individual state names.
- A line plot allows a reader to easily visualize the chronic change in educational spending, rather then requiring them to remember values in an animated choropleth map.
So, this is a plot, that someone could potentially use as a tool if they wanted to know the percentage of total child spending that spending in education comprised from 1998 to 2016 for any given state.
Suppose that a couple had the options of moving to Alabama, Indiana, or Alaska for job prospects. They could use this interactive plot to gauge how important education was to that state in a given year (from a fiscal perspective). Perhaps after looking at this, they could contact state representatives of Alabama why their proportional educational spending has decreased since 2008. This is not to suggest a family shouldn’t use other metrics to determine how good an education is, but it’s more useful information nonetheless.
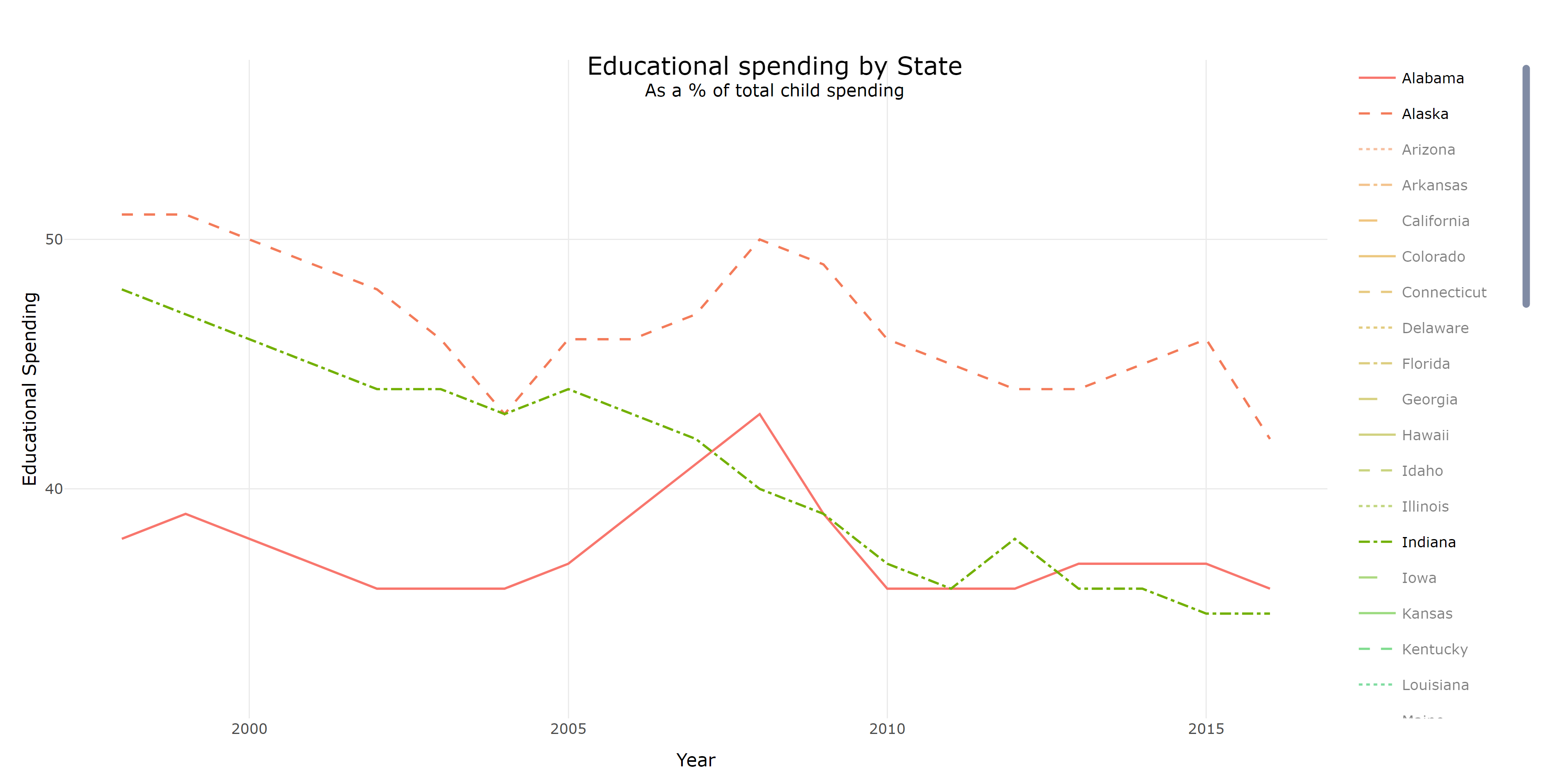
As for me, let’s see where I might have gotten the best education.
So New York has consistently spent more money on their children than New Jersey (rich jerks), but also consistently apportioned less of their overall budget to children’s education than New Jersey. Mo money mo problems, I guess?
Reflections and Learnings
This TidyTuesday post has come to an end. I’ve done much EDA and visualizations on data from the tidykids package. At first I chose to dig deeper into variables that excited me - ones that I felt were relevant to me as a child given the intersection of the time data and my life. These variables were any that related to education at large, libraries, and parks & rec. While I did initially plot a choropleth map for library and parks & rec spending, I decided not to pursue it any further; the amount of money state government spends on these is not much, and perhaps with good possible reason.
In the face of technology, libraries have greatly changed the services they offer society. Who needs to rent a book when you can pirate it to your tablet or buy the digital version? This is not to diminish the importance of the other services libraries offer (video media, language tools, classes, college and job prep), but to say that perhaps a library budget does not need to be as reactive as an education system’s budget.
The same rings true for parks & rec. Most public parks I know of have stayed the same for years, even decades.
Regardless, I’ve done a lot of new things in this post. I’ve made my first animation using gganimate, I got a lot of exposure to interactive plots using plotly. Going forward, I think I’d like to try out different interactive plotting packages such as leaflet if I wanted to tackle more choropleth maps and shiny if I wanted a bit more interactivity out of a chart.